
こんにちは。
初記事投稿のくろんです。
今回はタイトルにもある通り、
Switch用ソフト「あつまれ どうぶつの森」内のカブ価でグラフチャートを作った話です。
「あつまれ どうぶつの森」とは

自分だけの島に住んで、釣りをしたり、虫を捕まえたり、
服のデザインをしてみたり、住民とふれあったり、島を開拓したり、
カブを買ったり、カブで不労所得を得たり、カブでひと山当ててウハウハライフを送ったり、
できるゲームです。
…
はい、どうぶつの森のカブシステムが大好きな私です!
「どうぶつの森 カブ とは?」
今作「あつまれ どうぶつの森」のカブは日曜日午前中に
「ウリ」というキャラクターが自分の島に現れて買うことができます。

売りはタヌキ商店にて行うことができます。
売り値は月曜日から土曜日まで1日に2回午前・午後で変化し、
カブ売りのタイミングを見極め買い値より高く売ることで利益を得ることができます。
また、どうぶつの森のカブは1週間で腐ってしまう(売れなくなる)という特性も持っているため、
1週間のうち、一番高くなるタイミングを見極めることが重要となります。
まぁ、他の人の島でも売れるので。自分の島だけに固執する必要もありませんがね!!
というわけで、カブ価をグラフチャートにできたら、
なんとなく一番高いタイミングが分かるのではないかということで作り始めました。
コンセプト
「もう、カブ価をメモするのもめんどい…Twitterに画像上げとくからいい感じにやってくれー。」
という感じのものを作ろうと思っていたので、
入力はTwitterアカウントと期間だけにして極力減らしました。
イメージはこんな感じです。
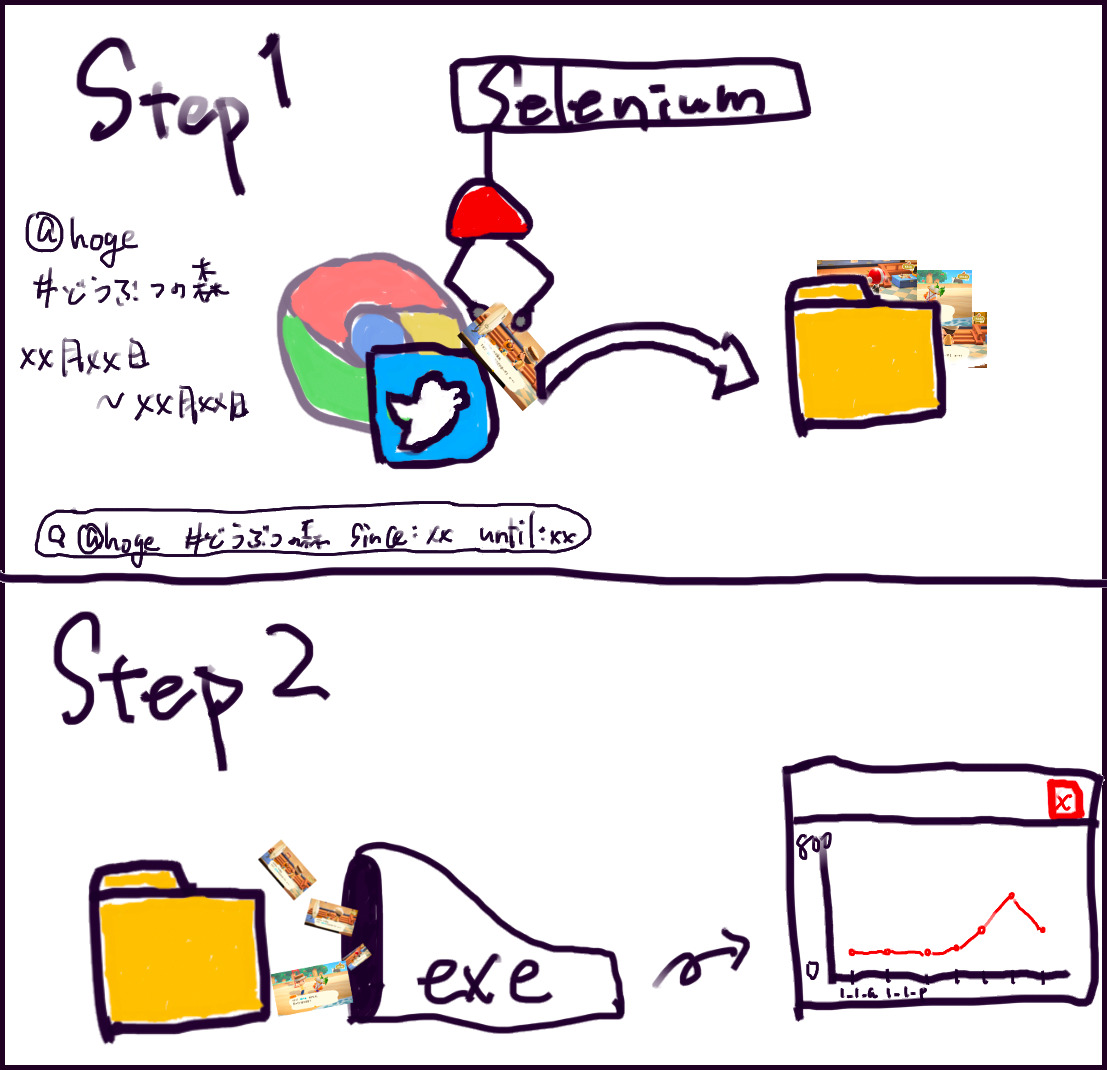
処理詳細
Seleniumを使って、Twitterより画像をDL
SeleniumはWebブラウザでの操作をプログラムで自動化できるフレームワークです。
TwitterAPIを使わない方法でどこまでできるか試すために、
今回はSeleniumを使用しています。
やっていることはTwitterをURLで開き、
そこに表示されている画像を保存するだけです。
① 検索文字列を含んだTwitterのURLを作って、ページにジャンプ
[https://twitter.com/search?q=”検索文字列 (@hogehoge #どうぶつの森)”&src=typed_query&f=live]
↓
② 最新のどうぶつの森スクリーンショットが表示されているのでclass や id タグから画像URLを探す
↓
③ 画像URLを使い画像をDLする
(画像のファイル名に日付と時間を入れておく)
こんな感じで画像を集めます。
# Python 3.7
from datetime import datetime
from datetime import timedelta
import time
import requests
from pytz import timezone
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
## DL期間指定
dateStart = datetime.strptime("2020-05-17", "%Y-%m-%d")
dateEnd = datetime.strptime("2020-05-23", "%Y-%m-%d")
## アカウント名
acountName = "@hogehoge"
## headless(ブラウザページ無し)
# options = Options()
# options.add_argument("--headless")
# driver = webdriver.Chrome(chrome_options=options)
## no headless(ブラウザページ有り)
driver = webdriver.Chrome()
for n in range((dateEnd - dateStart).days + 1):
d = dateStart + timedelta(days=n)
date = str(d.year) + "-" + str(d.month) + "-" + str(d.day)
## https://twitter.com/search?q=@hogehoge #どうぶつの森 since:YYYY-mm-dd_00:00:00_JST until:YYYY-mm-dd_23:59:59_JST&src=typed_query&f=live
driver.get("https://twitter.com/search?q=" + acountName +
"%20%23%E3%81%A9%E3%81%86%E3%81%B6%E3%81%A4%E3%81%AE%E6%A3%AE%20since%3A" +
date + "_00%3A00%3A00_JST%20until%3A" +
date + "_23%3A59%3A59_JST&src=typed_query&f=live")
## url開くの待たないとclass_nameが探せない
## (通信環境に依存)
time.sleep(3)
## 投稿1つづつ
article = driver.find_elements_by_class_name("css-1dbjc4n.r-1loqt21.r-16y2uox.r-1wbh5a2.r-1ny4l3l.r-1udh08x.r-1j3t67a.r-o7ynqc.r-6416eg")
for j in range(len(article)):
## UP画像含むdiv class_name(css-9pa8cd)はアイコンや絵文字にも使われているので、r-9x6qibに絞らないと
## 関係ない画像も引っかかる
imageBase = article[j].find_element_by_class_name("r-9x6qib")
try:
image = imageBase.find_element_by_class_name("css-9pa8cd")
except NoSuchElementException:
continue
## videoが投稿されているとバグるケースがあったので対処
try:
imageBase.find_element_by_tag_name("video")
continue
except NoSuchElementException:
pass
## 投稿時間を探す
dateBase = article[j].find_element_by_class_name("css-4rbku5.css-18t94o4.css-901oao.r-1re7ezh.r-1loqt21.r-1q142lx.r-1tl8opc.r-a023e6.r-16dba41.r-ad9z0x.r-bcqeeo.r-3s2u2q.r-qvutc0")
date = dateBase.find_element_by_tag_name("time").get_attribute("datetime")
utc = timezone("UTC").localize(datetime(int(date[0:4]), int(date[5:7]), int(date[8:10]), int(date[11:13]), int(date[14:16]), int(date[17:19])))
# print(utc)
jst = utc.astimezone(timezone("Asia/Tokyo"))
# print(jst)
url = image.get_attribute("src")
## たまに画像サイズがsmallとか900x900指定になっているのでorigで固定する
url = url.replace("small", "orig")
url = url.replace("900x900", "orig")
print(url)
if url == None:
continue
response = requests.get(url)
image = response.content
filename = str(jst.year) + "_" + str(jst.month).zfill(2) + "_" + str(jst.day).zfill(2) + "_"
if jst.hour <= 12:
filename = filename + "a_"
else:
filename = filename + "p_"
filename = filename + str(jst.hour).zfill(2) + str(jst.minute).zfill(2) + str(jst.second).zfill(2)
with open("imgs/" + filename + ".jpg", "wb") as i:
i.write(image)
driver.quit()
テンプレートマッチングでカブ価特定してグラフ表示
TwitterからDLしてきた画像を入力としてテンプレートマッチングを行います。
※ 各数字とシーン判別用のテンプレート画像はあらかじめ用意しています。
OpenCVを使っていい感じに検出できるので、
あとは価格と日付をまとめてグラフにプロットで終了です。
こちらはコードがGitHubに上がっているので詳しく気になる方は見てもらうとして、
単純に動かすだけであれば以下のリンクからexe と諸々が入ったものをDL&解凍してください。
https://github.com/ckron/GetKabukaFromDomori/releases/tag/v1.0
(使い方)
imgs フォルダにどうぶつの森スクリーンショットを入れて、
GetKabukaFromDomori.exeを実行するとグラフが表示されます。
実行環境
- Windows10 64bit
- Python 3.7.xxxx
- Selenium 3.141.0
- requests 2.23.0 (画像URLから画像DL)
- pytz 2020.1 (UTC → JST変換)
- Chrome Driver 83.0.4103.39
- Google Chrome 83.0.4103.106
環境設定
Selenium は動かすために色々と準備しておく必要があります。
必要なものは以下です。
- Miniconda
- Chrome Driver
- Google Chrome
- Python 3.7以上
- Selenium
- requests
- pytz
Miniconda&Python
Miniconda は公式からDLしてきてインストールでOKです。
https://docs.conda.io/en/latest/miniconda.html
※ Anacondaでもいいですが重いので、私はMinicondaをいつも使ってます。
インストールが終わったら、Anaconda Promptを開きます。
まずは今回使うConda環境を作ります。
conda create -n "環境名" python=3.7
Conda環境を作ることで、今回の一時的なプログラムが他の環境に影響を与えないようにします。
終わった後、いらないようなら
conda remove -n "環境名" --all
で作った環境ごと消せます。
作った環境の切り替えするためには、conda activate "環境名"を行います。
Pythonパッケージ
次に必要なパッケージをインストールします。
環境を切り替えた状態で
pip install selenium
pip install pytz
pip install requestsです。
※ conda install でもパッケージのインストールはできますが、selenium がない感じだったので pip install で統一しています。
conda install と pip install を混ぜて使うのはダメ絶対!!
ちゃんとパッケージが入っているかはconda listで確認できます。
Chrome Driver
Miniconda/Python/パッケージ が入ったら、Chrome Driverを探してきます。
https://chromedriver.chromium.org/downloads
Chrome Driver と Google Chrome のバージョンは揃えるのが無難なので、
インストールされている、Google Chrome のバージョンを確認しておきます。
①「・・・」が縦になっているやつを押す
↓
②「設定」を選択
↓
③「Chrome について」を押す
↓
④ バージョンが表示される!!
バージョンが分かったら同じバージョンのものをDL(Win32バージョンしかないのでそれでOK)
DLされたZIPファイルを解凍し、出てきたchromedriver.exeを実行するpythonファイルと一緒に入れておきます。
※ 一緒に入れておけば、環境変数にパスを設定しなくて済みます。
Chrome Driver がちゃんと使える状態かどうかは、Pythonの実行フォルダに移動して、chromedrive.exeを入力することで確認できます。
Starting ChromeDriver xx.x.xxxx.xx ...が表示されれば準備OKです。
ここまで終われば後は実行するだけです。
実行フォルダはこんな感じになっていると思います。
“実行フォルダ名” — img — 00_key — (テンプレート用画像)
|- imgs
|- chromedriver.exe
|- GetKabukaFromDomori.exe
|- opencv_world430.dll
L hogehoge.py
実行コマンドはこんな感じです。
① python hogehoge.py
② GetKabukaFromDomori.exe
バッチファイルにまとめておくと楽ですよ。
①②を実行することでグラフの表示までできます。
実行結果
実行するとこんな感じになります。
画像DL中…
グラフ表示!
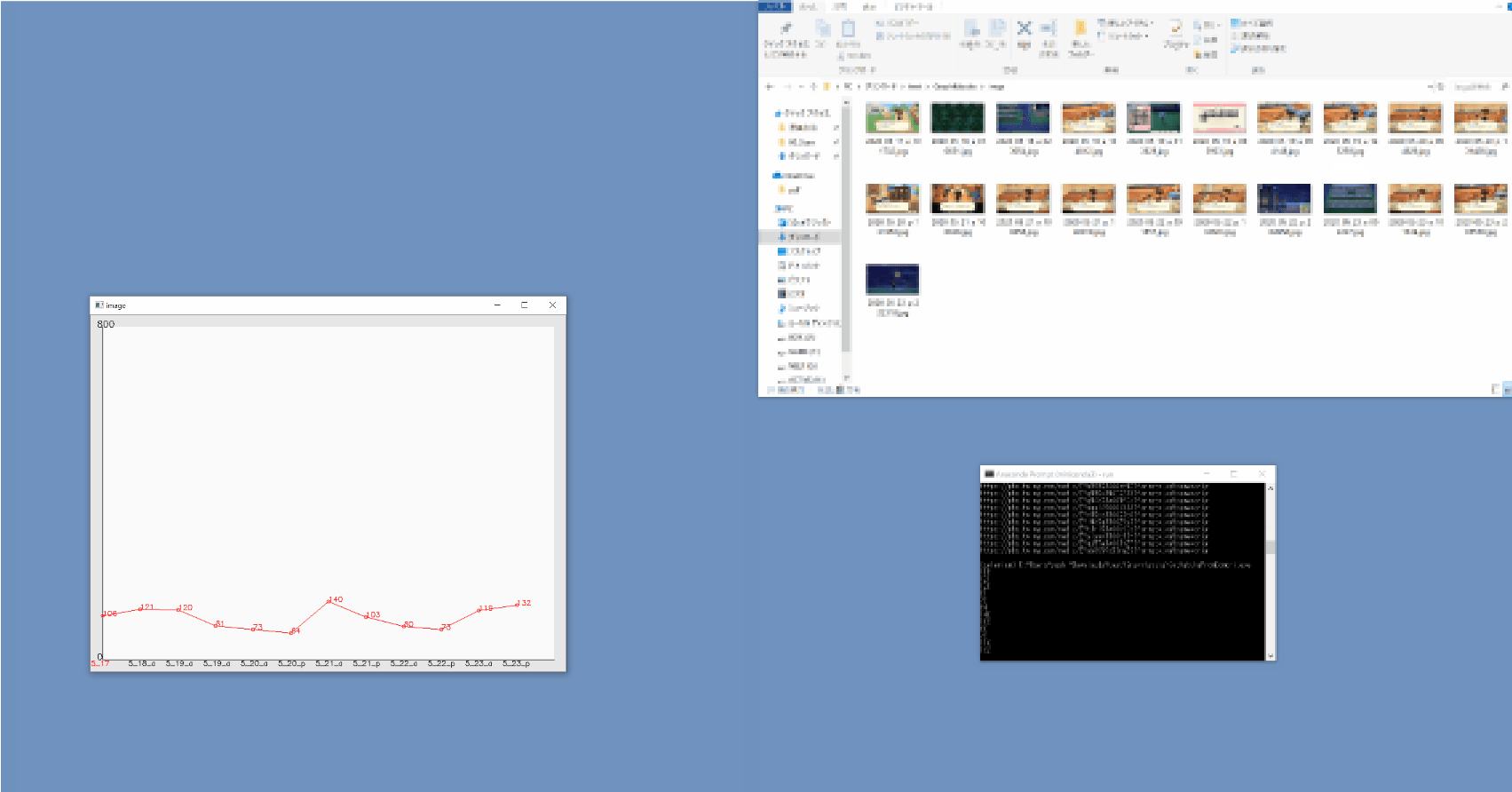
今のところ確認している弱点は
ツイートを表示してDLするくだりで、たくさん出ちゃうと下の方に表示されているツイート画像がDLできなくなるところですかね。(4ツイート位なら大丈夫)
今作のどうぶつの森のカブ価変動には4つのパターンがあるという噂があります。
出来上がったグラフと照らし合わせてみれば、何かが見えてくるかもしれませんね。
…
というわけで今回は
– TwitterAPIを通さない
– 画像からカブ価を取得
– カブ価をグラフ表示
するプログラムを作ってみました!
Windows10 64bit だったら動くはずなので、
よかったら使ってみてください!!
では!

Nintendo Switch 本体 (ニンテンドースイッチ) Joy-Con(L) ネオンブルー/(R) ネオンレッド(バッテリー持続...


Selenium実践入門 ――自動化による継続的なブラウザテスト WEB+DB PRESS plus




コメント